
월간 데이콘 항공편 지연 예측 AI 경진대회
notion : https://www.notion.so/jung110/DAYCON-0e5c3a3b7c06479ebbfa4661a8a8cc22?pvs=4
- public 0.64
- private 0.83
환경 설정 및 데이터 불러오기
# 전처리
import pandas as pd
import numpy as np
import random
import os
import gc
# 시각화
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 모델링 및 전처리
import catboost
from catboost import CatBoostClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import RobustScaler
# 이 함수 사용시 모든 랜덤값이 돌릴때마다 똑같이 나옴
def seed_everything(seed):
'''
모든 시드값을 지정값으로 고정
'''
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
seed_everything(42) # Seed 고정
def csv_to_parquet(csv_path, save_name):
'''
csv형식의 파일을 parquet형식으로 바꿈
'''
df = pd.read_csv(csv_path)
df.to_parquet(f'./{save_name}.parquet')
del df
gc.collect()
print(save_name, 'Done.')
# csv 파일을 parquet 형식으로 변환
csv_to_parquet('./daycon_airplane/train.csv', 'train')
csv_to_parquet('./daycon_airplane/test.csv', 'test')
# 데이터 불러오기
train = pd.read_parquet('./train.parquet')
test = pd.read_parquet('./test.parquet')
sample_submission = pd.read_csv('daycon_airplane/sample_submission.csv', index_col = 0)EDA
air_state = \
dict(train[['Destination_Airport','Destination_State']].value_counts().index)
state_mode = pd.concat([train['Origin_State'],train['Destination_State']]).mode()[0]
def get_state_from_airport(x):
try:
return air_state[x]
except:
return state_mode
train['Destination_State'] = \
train['Destination_Airport']\
.apply(get_state_from_airport)
test['Destination_State'] = \
test['Destination_Airport']\
.apply(get_state_from_airport)
train['Origin_State'] = \
train['Origin_Airport']\
.apply(get_state_from_airport)
test['Origin_State'] = \
test['Origin_Airport']\
.apply(get_state_from_airport)
# 각 공항별 , 주 별 빈도수 그래프
fig , (ax1, ax2) = plt.subplots(2,1,figsize = [10,10])
a = sns.countplot(x = 'Destination_State',data=train, ax= ax1)
ax1.set_xticklabels(a.get_xticklabels() , rotation = 90)
b = sns.countplot(x = 'Destination_Airport',data=train, ax= ax2)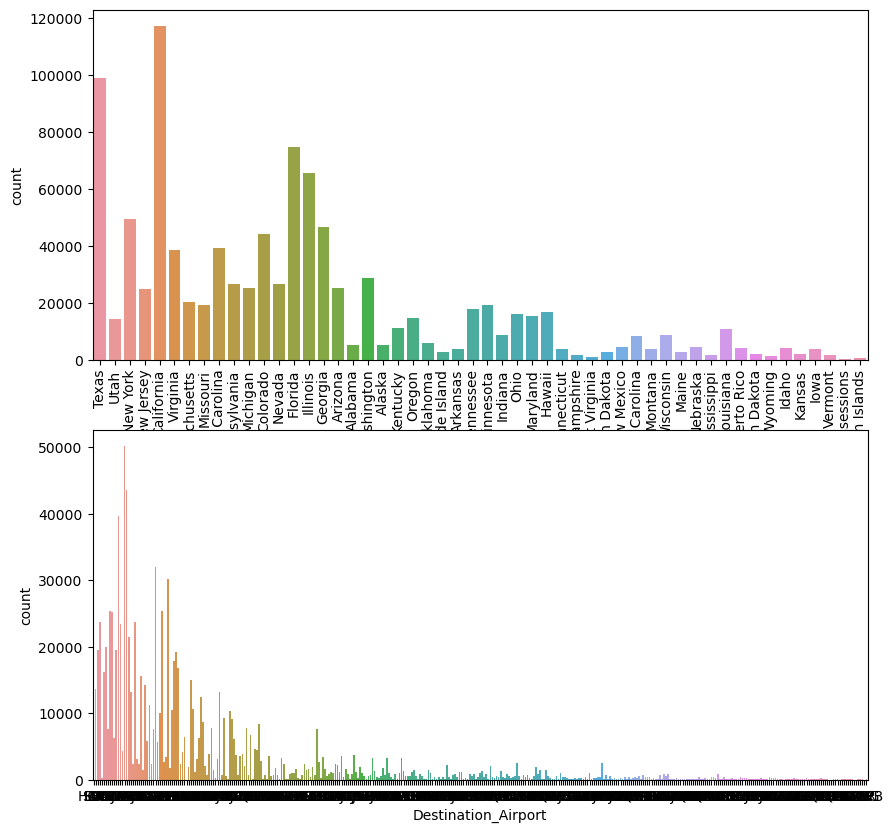
plt.figure(figsize = [20,10])
sns.countplot(x = 'Airline' , data = train )
plt.xticks(rotation = 90)
plt.show()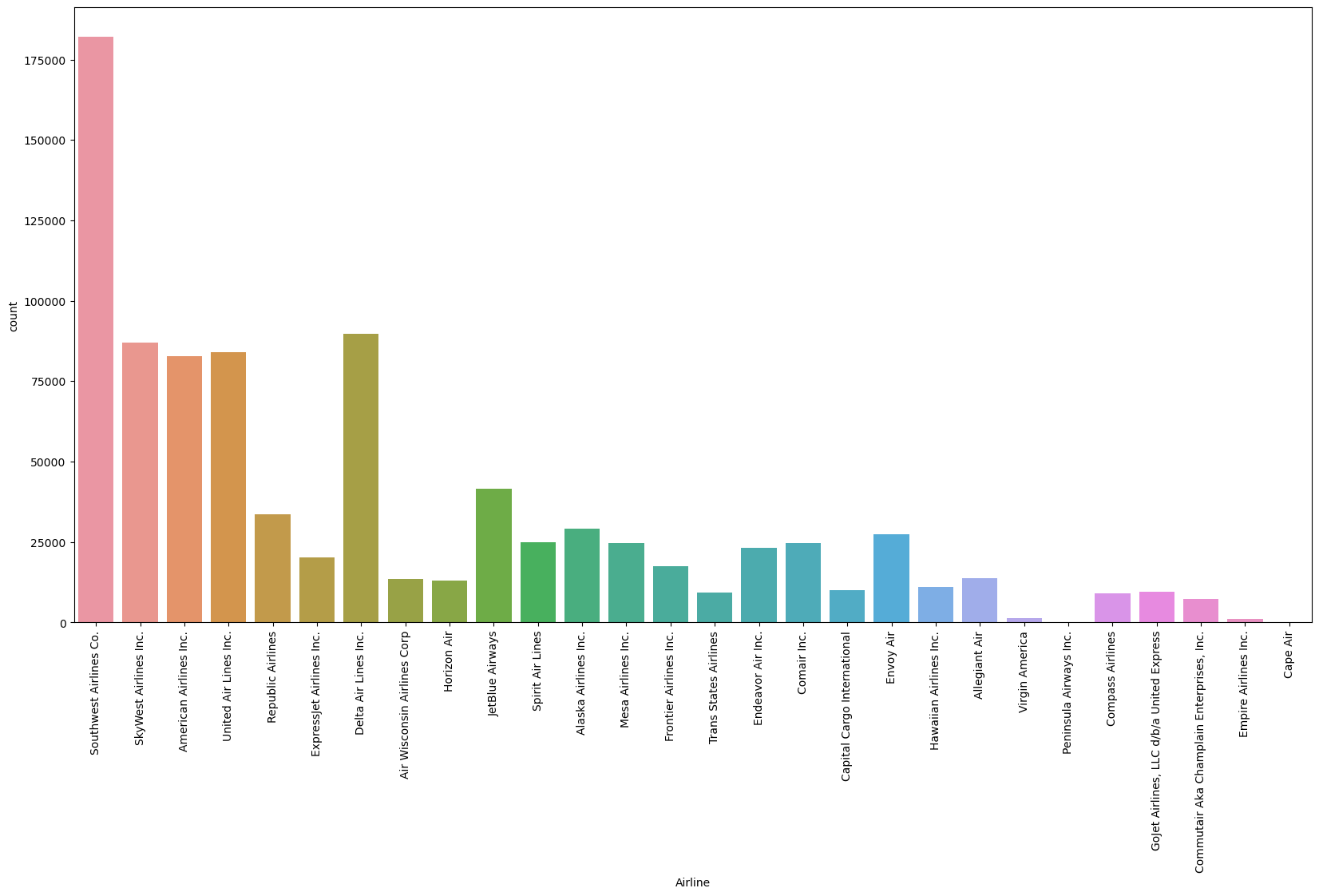
os_df = train[['Origin_State','Airline']]
ds_df = train[['Destination_State', 'Airline']]
os_df.columns = ['State', 'Airline']
ds_df.columns = ['State', 'Airline']
state_air_df.dropna()| State | Airline | |
|---|---|---|
| 0 | Oklahoma | Southwest Airlines Co. |
| 1 | Illinois | SkyWest Airlines Inc. |
| 2 | North Carolina | American Airlines Inc. |
| 3 | California | United Air Lines Inc. |
| 4 | California | SkyWest Airlines Inc. |
| ... | ... | ... |
| 999994 | California | SkyWest Airlines Inc. |
| 999995 | Pennsylvania | United Air Lines Inc. |
| 999996 | Minnesota | SkyWest Airlines Inc. |
| 999997 | Texas | Southwest Airlines Co. |
| 999998 | Georgia | Delta Air Lines Inc. |
1782160 rows × 2 columns
항공사 결측치 채우기
공항별 최빈값 으로 1차로 채우기
주별 최빈값으로 나머지 전부 채우기
# 공항별 항공사 최빈값을 구하여 dict로 저장한다.
oa_df = train[['Origin_Airport','Airline']]
da_df = train[['Destination_Airport', 'Airline']]
oa_df.columns = ['Airport', 'Airline']
da_df.columns = ['Airport', 'Airline']
port_air_df = pd.concat([oa_df,da_df])
port_air_df.dropna(inplace=True)
airport_list = port_air_df['Airport'].unique()
airline_list = []
port_air_count = port_air_df.value_counts()
for airport in airport_list:
airline_list.append(port_air_count[airport].index[0])
airport_airline_dict = dict(zip(airport_list , airline_list))
# 주별 항공사 최빈값을 구하여 dict로 저장한다.
os_df = train[['Origin_State','Airline']]
ds_df = train[['Destination_State', 'Airline']]
os_df.columns = ['State', 'Airline']
ds_df.columns = ['State', 'Airline']
state_air_df = pd.concat([os_df,ds_df])
state_air_df.dropna(inplace=True)
state_list = state_air_df['State'].unique()
airline_list = []
state_air_count = state_air_df.value_counts()
for state in state_list:
airline_list.append(state_air_count[state].index[0])
state_airline_dict = dict(zip(state_list , airline_list))
def fill_airline_na(x):
try :
return airport_airline_dict[x[0]]
except:
try:
return state_airline_dict[x[1]]
except:
return np.nan
train['Airline'].loc[train['Airline'].isna()] = \
train[['Origin_Airport','Origin_State']].loc[train['Airline'].isna()].apply(
fill_airline_na, axis = 1
)
test['Airline'].loc[test['Airline'].isna()] = \
test[['Origin_Airport','Origin_State']].loc[test['Airline'].isna()].apply(
fill_airline_na, axis = 1
)나머지 데이터는 최빈값으로 채우기
#레이블(Delay)을 제외한 결측값이 존재하는 변수들을 학습 데이터의 최빈값으로 대체합니다
NaN_col = ['Estimated_Departure_Time', 'Estimated_Arrival_Time','Carrier_Code(IATA)','Carrier_ID(DOT)']
for col in NaN_col:
mode = train[col].mode()[0]
train[col] = train[col].fillna(mode)
if col in test.columns:
test[col] = test[col].fillna(mode)
print('Done.')질적 변수(범주형 변수)을 수치화
#질적 변수들을 수치화합니다
qual_col = ['Origin_Airport', 'Origin_State', 'Destination_Airport', 'Destination_State', 'Airline', 'Carrier_Code(IATA)', 'Tail_Number']
for i in qual_col:
le = LabelEncoder()
le=le.fit(train[i])
train[i]=le.transform(train[i])
for label in np.unique(test[i]):
if label not in le.classes_:
le.classes_ = np.append(le.classes_, label)
test[i]=le.transform(test[i])
print('Done.')Self_Trainning
- Catboost를 사용하여 셀프 트레이닝을 실시한다.
- RobustScaler를 사용하여 data Scaling 을 진행한다.
cat = CatBoostClassifier(learning_rate = 0.005)
rb = RobustScaler()# 레이블이 없는 값의 df
unlabeled = train[train['Delay'].isna()]
iter_n = 0
before_length = 0
# 50번 반복되거나, 모든 값이 레이블값을 가지거나 더 이상 conf > 0.9 인 값이 나오지 않으면 반복을 종료한다.
while (len(unlabeled) != 0) & (iter_n <50) &(before_length != len(unlabeled) ):
# 레이블이 있는 값을 분리한다.
labeled = train.dropna()
# RobustScaler을 사용하여 data Scaling 을 진행한다.
labeled_x = rb.fit_transform(labeled.drop(['ID','Delay' ], axis =1))
labeled_y = labeled['Delay']
# CatBoost 모델을 레이블된 데이터를 이용하여 훈련한다.
cat.fit(labeled_x, labeled_y, silent = True)
# 해당 모델을 이용하여 unlabeled 데이터의 각 class별 확률을 구해준다.
proba_unlabeled = cat.predict_proba(rb.fit_transform(unlabeled.drop(columns=['ID' , 'Delay'])))
proba_unlabeled = pd.DataFrame(data = proba_unlabeled , columns= cat.classes_)
# 이 중 0.9를 넘는 확률을 가지는 값만을 새로운 labeled 데이터로 추가해준다.
proba_unlabeled['Delay'] = proba_unlabeled[['Delayed','Not_Delayed']].apply(
lambda x :'Delay' if x[0] >= 0.9 else 'Not_Delayed' if x[1]>=0.9 else np.nan,
axis = 1
)
# 추가된 레이블데이터가 있는지 확인
before_length = len(unlabeled)
# 레이블 데이터 추가 후 다시 처음 부터 해준다.
train['Delay'].loc[train['Delay'].isna()] = proba_unlabeled.loc[:,'Delay']
unlabeled = train[train['Delay'].isna()]
print("{}: nan num -> {} ".format(iter_n , len(unlabeled)))
# 반복횟수 + 1
iter_n+=1autogluon을 사용하여 최적의 모델 찾아서 훈련시키기
# 레이블이 없는 데이터를 제거합니다.
train = train.dropna()
# not_delayed = 0 , delayed = 1 변환
column_number = {}
for i, column in enumerate(sample_submission.columns):
column_number[column] = i
def to_number(x, dic):
return dic[x]
train.loc[:, 'Delay_num'] = \
train['Delay'].apply(lambda x: to_number(x, column_number))
# autogluon에 정형 데이터를 처리하는 라이브러리를 불러온다.
from autogluon.tabular import TabularDataset, TabularPredictor
train = TabularDataset(train.drop('Delay_num' , axis = 1))
test = TabularDataset(test.drop('ID' , axis = 1))
# 훈련
predictor = TabularPredictor(label='Delay', eval_metric='f1_macro',)\
.fit(train)# 제일 score(f1_macro)가 좋은 모델을 사용하여 각 class별 확률을 출력한다.
pred_y = predictor.predict_proba(test)
submission = pd.DataFrame(data=np.array(pred_y),
columns=sample_submission.columns,
index=sample_submission.index)
submission.to_csv('baseline_submission.csv', index=True)